Modélisation et incertitudes : construction fine du modèle
Durée estimée et travail à réaliser
Pour cette troisième partie, compter 20 minutes et 10 minutes de mise en commun.
L'élève a représenté le nuage de points et a identifié une relation de proportionnalité entre l'intensité \(i\) du courant dans la résistance et la tension \(u\) à ses bornes. Il cherche à modéliser la caractéristique du dipôle à l'aide d'une régression linéaire (programmation en Python) et à évaluer par une approche statistique l'incertitude-type sur la série de valeurs.
Remarque : Hypothèse de proportionnalité
Sous la direction du professeur, l'élève portera un regard critique sur les choix opérés pour modéliser le comportement du dipôle testé.
Compte tenu de ce qu'il a appris au collège, l'élève fera l'hypothèse de la proportionnalité entre i et u. Il devra construire, par une analyse statistique à deux variables avec \(i[]\) et \(u[]\), la droite d'ajustement \(u=a\times i+b\).
Les analyses statistiques seront menées en important le fichier de mesures dans le tableau de Geogebra, puis en activant les outils appropriés.
Ensuite, l'élève construit les lignes de programme en Python pour produire le modèle linéaire.
Droite d'ajustement ou régression linéaire
Méthode : Programmation en Python
Il est utile d'importer le module stats de la librairie scipy. Il existe également des outils statistiques dans la librairie numpy.
import scipy.stats as st
Déterminer les paramètres \((a, b)\) dans le modèle \(u=a\times i+b\) à l'aide de l'outil linregress.
#Etude statistiquea, b, r_value, p_value, std_err = st.linregress(i, u)
Générer la liste comprenant les valeurs \(\left[ a\times i_1+b,\;a\times i_2+b, \;\cdots \;,a\times i_n+b\right]\)
Pour cela, créer la fonction predict.
def predict(x,slope, intercept):
return slope * x + intercept
L'appeler dans le programme avec :
modele = predict(i, a, b)
Après la ligne créant le nuage de points, insérer la ligne créant le modèle linéaire.
plt.plot(1000*i, modele, c='r', label='modèle linéaire')
Remarque : Modèle affine
En raison d'erreurs systématiques[1], le modèle trouvé peut ne pas être rigoureusement \(u=R\times i\). Cependant la meilleure estimation de la résistance \(R\) du conducteur ohmique est le coefficient \(a\) de l'ajustement linéaire déterminé par la méthode des moindres carrés.
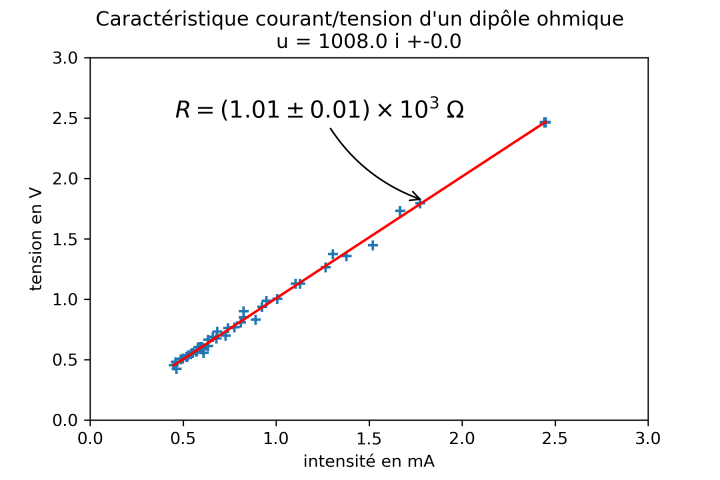
L'étude statistique à deux variables (droite d'ajustement) est satisfaisante. On obtient une équation affine cohérente. La pente a est le meilleur estimateur de la valeur de la résistance.
Mais une analyse statistique est nécessaire pour déterminer l'incertitude-type sur la pente a.
Il est possible de représenter les barres d'erreur.
Incertitude-type sur le coefficient a, résultat final et comparaison avec la valeur de référence
Avec Geogebra
Par analyse statistique du tableau de i et u dans Geogebra, on note :
\(u=a\times i+b\)
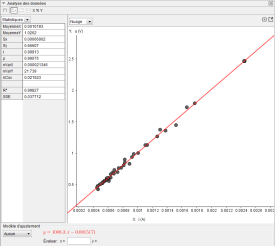
Erreur standard de l'estimation
#Etude statistiquea, b, r_value, p_value, std_err = st.linregress(i, u)
La variable std_err contient l'erreur standard de l'estimation.
« Par définition, l'erreur type d'une méthode d'estimation est l'écart type de l'estimateur utilisé. »
On prendra cette valeur pour évaluer l'incertitude type sur le coefficient directeur de la droite d'ajustement.
Conseil : Écriture du résultat final
Quelle écriture retenir du résultat du mesurage ?
En classe de seconde, on ne traite pas l'incertitude de type A complète avec le facteur d'élargissement lié à un niveau de confiance. On s'intéresse à l'écart-type de la moyenne comme un bon indicateur de l'estimation de l'erreur.
On peut, pour conclure cette activité, demander à écrire le résultat du mesurage avec 3 chiffres significatifs et une majoration de l'incertitude-type \(u(R)\).
\(R=\left( 1{,}01\pm 0{,}01 \right)\times 10^{3} \;\Omega\)
Pour cela, on peut définir la fonction notation() dont les arguments sont la valeur, l'incertitude-type et le nombre de chiffre significatifs :
def notation(valeur, erreur, cs):
n = int(np.log10(valeur))
a = round(valeur/10**n,cs)
err = round(erreur/10**n,cs)
sortie = "\\left("+str(a)+" \\pm"+str(err)+" \\right) \\times 10^{"+str(n)+"}"
return sortie
... et appeler cette fonction pour afficher le résultat final sur le graphique :
legende = r"$R="+notation(a, std_err, 3)+"\;\Omega$"
t = 0.6*i_max
# On annote le modèle en précisant la pente et son incertitude-typeplt.annotate(legende,xy=(t, a*t/1000+b), xycoords='data',xytext=(-150, +50), textcoords='offset points', fontsize=14, arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2"))
Complément : Mesures répétées avec un nombre de points différent
Comment évolue l'incertitude-type lorsqu'on répète, dans les mêmes conditions, le mesurage de la résistance d'un conducteur ohmique avec un nombre de points croissant ?
Pour répondre à cette question, exploiter les données du mesurage avec 10, 20, 30, 40, 50, 100 et 200 points en téléchargeant le classeur Excel ci-dessous.
A la page suivante, vous répondrez dans un cas de figure en saisissant la valeur numérique de l'incertitude-type.